Зачем:
Думаю многие слышали про дистрибутив gentoo, как и про то, что его обновление может занимать часы (дни, месяцы, годы, …). Такой геморрой определён политикой дистрибутива, так называемый source-based. То есть компиляция всего и вся из исходников. И в этом есть свой профит. Если вы собираете программу на своём компьютере и прописываете определённые флаги компиляции, то конечный исполняемый файл оптимизируется именно под ваш процессор. Да, прирост производительности может быть небольшим, незаметным глазу, но за счёт количества пересобранных приложений достигается ощутимый выигрыш в скорости работы системы (по идее).
С ядром же история несколько иная. Да, компиляция под себя оптимизирует ядро под ваш проц, но есть ещё один важный нюанс. Патчи.
Их огромное количество и я при всём желании не смогу описать их все. Тем более что они описаны на арчевики.
Мой рандомайзер выстрелил в список и попал в патч linux-pf.
Кстати вот статейка на хабре, ему посвящёна. В этой статье приведены какие-то таблицы, созданные с помощью UnixBench. Я не поленился и прогнал этот бенчмарк у себя. Так как выхлоп слишком большой я заменю его ссылочками на pastebin.
Ядро mainline — типа экспериментальная версия, которая в манжаре уже собрана (но без драйверов и важных финтифлюшек), и которую я собрал на арче сам чисто по приколу.
========================================================================
BYTE UNIX Benchmarks (Version 5.1.3)
System: archlinux: GNU/Linux
OS: GNU/Linux -- 5.3.0-rc4-mainline -- #1 SMP PREEMPT Mon Aug 12 18:38:59 MSK 2019
Machine: x86_64 (unknown)
Language: en_US.utf8 (charmap="UTF-8", collate="UTF-8")
CPU 0: Intel(R) Core(TM) i7-4700MQ CPU @ 2.40GHz (4790.4 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET, Intel virtualization
CPU 1: Intel(R) Core(TM) i7-4700MQ CPU @ 2.40GHz (4790.4 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET, Intel virtualization
CPU 2: Intel(R) Core(TM) i7-4700MQ CPU @ 2.40GHz (4790.4 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET, Intel virtualization
CPU 3: Intel(R) Core(TM) i7-4700MQ CPU @ 2.40GHz (4790.4 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET, Intel virtualization
CPU 4: Intel(R) Core(TM) i7-4700MQ CPU @ 2.40GHz (4790.4 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET, Intel virtualization
CPU 5: Intel(R) Core(TM) i7-4700MQ CPU @ 2.40GHz (4790.4 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET, Intel virtualization
CPU 6: Intel(R) Core(TM) i7-4700MQ CPU @ 2.40GHz (4790.4 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET, Intel virtualization
CPU 7: Intel(R) Core(TM) i7-4700MQ CPU @ 2.40GHz (4790.4 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET, Intel virtualization
03:37:14 up 2 min, 1 user, load average: 3.10, 1.90, 0.76; runlevel unknown
------------------------------------------------------------------------
Benchmark Run: Вс авг 18 2019 03:37:14 - 04:05:37
8 CPUs in system; running 1 parallel copy of tests
Dhrystone 2 using register variables 34169001.9 lps (10.0 s, 7 samples)
Double-Precision Whetstone 5421.1 MWIPS (9.4 s, 7 samples)
Execl Throughput 3016.0 lps (29.9 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 410703.4 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 96583.2 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 1148064.9 KBps (30.0 s, 2 samples)
Pipe Throughput 503500.0 lps (10.0 s, 7 samples)
Pipe-based Context Switching 49623.9 lps (10.0 s, 7 samples)
Process Creation 2992.2 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 2130.3 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 764.0 lpm (60.0 s, 2 samples)
System Call Overhead 271406.7 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 34169001.9 2927.9
Double-Precision Whetstone 55.0 5421.1 985.7
Execl Throughput 43.0 3016.0 701.4
File Copy 1024 bufsize 2000 maxblocks 3960.0 410703.4 1037.1
File Copy 256 bufsize 500 maxblocks 1655.0 96583.2 583.6
File Copy 4096 bufsize 8000 maxblocks 5800.0 1148064.9 1979.4
Pipe Throughput 12440.0 503500.0 404.7
Pipe-based Context Switching 4000.0 49623.9 124.1
Process Creation 126.0 2992.2 237.5
Shell Scripts (1 concurrent) 42.4 2130.3 502.4
Shell Scripts (8 concurrent) 6.0 764.0 1273.4
System Call Overhead 15000.0 271406.7 180.9
========
System Benchmarks Index Score 621.9
------------------------------------------------------------------------
Benchmark Run: Вс авг 18 2019 04:05:37 - 04:33:56
8 CPUs in system; running 8 parallel copies of tests
Dhrystone 2 using register variables 80371026.4 lps (10.0 s, 7 samples)
Double-Precision Whetstone 35358.2 MWIPS (10.8 s, 7 samples)
Execl Throughput 7521.7 lps (29.9 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 196291.0 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 64360.9 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 733168.9 KBps (30.0 s, 2 samples)
Pipe Throughput 873622.1 lps (10.0 s, 7 samples)
Pipe-based Context Switching 92215.8 lps (10.0 s, 7 samples)
Process Creation 9947.5 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 10548.6 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 1492.0 lpm (60.1 s, 2 samples)
System Call Overhead 1201385.6 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 80371026.4 6887.0
Double-Precision Whetstone 55.0 35358.2 6428.8
Execl Throughput 43.0 7521.7 1749.2
File Copy 1024 bufsize 2000 maxblocks 3960.0 196291.0 495.7
File Copy 256 bufsize 500 maxblocks 1655.0 64360.9 388.9
File Copy 4096 bufsize 8000 maxblocks 5800.0 733168.9 1264.1
Pipe Throughput 12440.0 873622.1 702.3
Pipe-based Context Switching 4000.0 92215.8 230.5
Process Creation 126.0 9947.5 789.5
Shell Scripts (1 concurrent) 42.4 10548.6 2487.9
Shell Scripts (8 concurrent) 6.0 1492.0 2486.7
System Call Overhead 15000.0 1201385.6 800.9
========
System Benchmarks Index Score 1229.7
Патченное ядро linux-pf.
========================================================================
BYTE UNIX Benchmarks (Version 5.1.3)
System: archlinux: GNU/Linux
OS: GNU/Linux -- 5.2.5-pf -- #1 SMP PREEMPT Sun Aug 18 01:54:40 MSK 2019
Machine: x86_64 (unknown)
Language: en_US.utf8 (charmap="UTF-8", collate="UTF-8")
CPU 0: Intel(R) Core(TM) i7-4700MQ CPU @ 2.40GHz (15963.0 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET, Intel virtualization
CPU 1: Intel(R) Core(TM) i7-4700MQ CPU @ 2.40GHz (15963.0 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET, Intel virtualization
CPU 2: Intel(R) Core(TM) i7-4700MQ CPU @ 2.40GHz (15963.0 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET, Intel virtualization
CPU 3: Intel(R) Core(TM) i7-4700MQ CPU @ 2.40GHz (15963.0 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET, Intel virtualization
CPU 4: Intel(R) Core(TM) i7-4700MQ CPU @ 2.40GHz (15963.0 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET, Intel virtualization
CPU 5: Intel(R) Core(TM) i7-4700MQ CPU @ 2.40GHz (15963.0 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET, Intel virtualization
CPU 6: Intel(R) Core(TM) i7-4700MQ CPU @ 2.40GHz (15963.0 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET, Intel virtualization
CPU 7: Intel(R) Core(TM) i7-4700MQ CPU @ 2.40GHz (15963.0 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET, Intel virtualization
02:27:30 up 14 min, 1 user, load average: 3.07, 2.62, 1.87; runlevel unknown
------------------------------------------------------------------------
Benchmark Run: Вс авг 18 2019 02:27:30 - 02:55:26
8 CPUs in system; running 1 parallel copy of tests
Dhrystone 2 using register variables 28102565.1 lps (10.0 s, 7 samples)
Double-Precision Whetstone 5322.5 MWIPS (7.7 s, 7 samples)
Execl Throughput 3065.8 lps (29.7 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 424274.1 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 111489.1 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 1216662.6 KBps (30.0 s, 2 samples)
Pipe Throughput 614354.3 lps (10.0 s, 7 samples)
Pipe-based Context Switching 146982.7 lps (10.0 s, 7 samples)
Process Creation 6229.7 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 3328.3 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 1092.1 lpm (60.0 s, 2 samples)
System Call Overhead 348862.5 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 28102565.1 2408.1
Double-Precision Whetstone 55.0 5322.5 967.7
Execl Throughput 43.0 3065.8 713.0
File Copy 1024 bufsize 2000 maxblocks 3960.0 424274.1 1071.4
File Copy 256 bufsize 500 maxblocks 1655.0 111489.1 673.7
File Copy 4096 bufsize 8000 maxblocks 5800.0 1216662.6 2097.7
Pipe Throughput 12440.0 614354.3 493.9
Pipe-based Context Switching 4000.0 146982.7 367.5
Process Creation 126.0 6229.7 494.4
Shell Scripts (1 concurrent) 42.4 3328.3 785.0
Shell Scripts (8 concurrent) 6.0 1092.1 1820.2
System Call Overhead 15000.0 348862.5 232.6
========
System Benchmarks Index Score 805.9
------------------------------------------------------------------------
Benchmark Run: Вс авг 18 2019 02:55:26 - 03:23:44
8 CPUs in system; running 8 parallel copies of tests
Dhrystone 2 using register variables 77432227.4 lps (10.0 s, 7 samples)
Double-Precision Whetstone 22659.5 MWIPS (8.4 s, 7 samples)
Execl Throughput 8654.5 lps (29.8 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 684336.4 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 199066.7 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 1899537.2 KBps (30.0 s, 2 samples)
Pipe Throughput 3647132.9 lps (10.0 s, 7 samples)
Pipe-based Context Switching 222343.4 lps (10.0 s, 7 samples)
Process Creation 50463.7 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 15001.1 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 1018.2 lpm (60.2 s, 2 samples)
System Call Overhead 2216016.2 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 77432227.4 6635.2
Double-Precision Whetstone 55.0 22659.5 4119.9
Execl Throughput 43.0 8654.5 2012.7
File Copy 1024 bufsize 2000 maxblocks 3960.0 684336.4 1728.1
File Copy 256 bufsize 500 maxblocks 1655.0 199066.7 1202.8
File Copy 4096 bufsize 8000 maxblocks 5800.0 1899537.2 3275.1
Pipe Throughput 12440.0 3647132.9 2931.8
Pipe-based Context Switching 4000.0 222343.4 555.9
Process Creation 126.0 50463.7 4005.1
Shell Scripts (1 concurrent) 42.4 15001.1 3538.0
Shell Scripts (8 concurrent) 6.0 1018.2 1697.0
System Call Overhead 15000.0 2216016.2 1477.3
========
System Benchmarks Index Score 2298.0
Насколько я понял, тест прогонялся в однопоточном и восьмипоточном режимах. И если для одного потока конечный балл не сильно различается (621 для mainline и 805 для pf), то для многопоточного режима разница уже ппц как ощутима (2298 для pf и 1229 для mainline).
Опишу немного что было протестировано:
- Dhrystone — используется для измерения и сравнения производительности компьютеров. (и сами понимайте что это значит, я не понял).
- Double-Precision — используется для измерения скорости и эффективности операций с плавающей запятой.
- Execl Throughput — используется для измерения количества вызовов execl, которые могут быть выполнены в секунду.
- File Copy — используется для измерения скорости, с которой данные могут передаваться из одного файла в другой. При тестировании изменяется размер блоков для копирования и их количество.
- Pipe Throughput — сколько раз (в секунду) процесс может записать 512 байт в канал и прочитать их обратно.
- Process creation — время создания потока
- Shell scripts — сколько раз в секунду можно запустить скрипты на shell
- Systyem call overload — задержки системных вызовов
На стандартном ядре арча я запускать тест не стал, потому что мне лениво ждать ещё пол-часа. Но не думаю что результат будет сильно отличаться от linux-mainline, так как он был собран с дефолтным конфигом арча.
Если вас впечатлили результаты тестов и вам захочется собрать для себя ядро linux-pf, то вот кратенький инструкшн
yay -S linux-pf
ВАЖНО!!!
Так как ядро большое и собираться будет долго, то настоятельно вам советую поправить /etc/makepkg.conf в соответствии с мануалом. Внимательно смотреть на секцию «Настройка: архитектура и флаги компиляции» и всё что ниже.
ВАЖНО!!!
Сборка потребует от юзера тыкать на кнопочки, поэтому pamac и octopi сразу пролетают. Сразу юзайте консольные утилиты во избежание баттхерта.
В процессе сборки ядра вас 2 раза будут спрашивать, надо ли вам что-то изменить: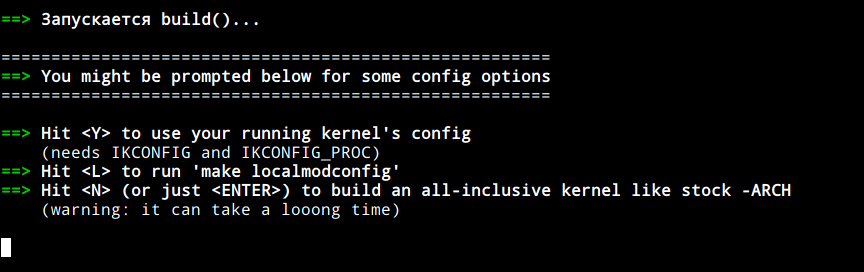 Running kernel config выбирать бессмысленно, так как у вас он будет таким же, как дефолтная опция. А вот make localmodconfig уже интереснее: он настроит ядро на сборку только тех модулей, что сейчас используются.
Running kernel config выбирать бессмысленно, так как у вас он будет таким же, как дефолтная опция. А вот make localmodconfig уже интереснее: он настроит ядро на сборку только тех модулей, что сейчас используются.
Это позволяет не собирать кучу ненужных драйверов и всякого мусора, но так же может выстрелить вам в ногу (как мне). Например если вы захотите скинуть данные на флешку или внешний хард, то система (ядро) ваше устройство просто не увидит, так как за это отвечает отдельный модуль, который конечно же собран не был. Он бы собрался, если бы вы при сборке ядра воткнули в комп флешку. И таких неочевидных мест довольно много: за сеть в виртуальной машине отвечает отдельный модуль (за саму вирутализацию тоже). Поэтому используйте эту опцию если уверены в своих силах и вам хватит воли и терпения пересобирать ядро несколько раз, чтобы включить недостающий модуль.
Конечно проще нажать энтер и собрать олл-инклюзив, и оно даже будет работать, но это не по-гиковски)
И второй вопрос, сразу после первого:
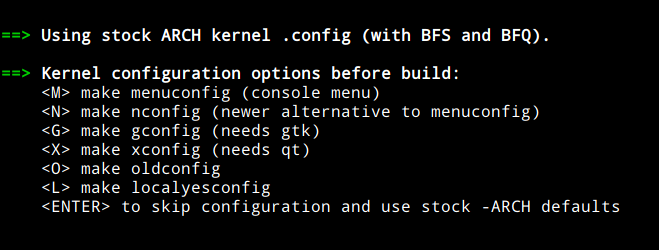 Это опции «досборки» ядра. Если вам позарез надо включить какую-то фичу или добавить модуль. Первые четыре опции отличаются только графикой, с помощью которой будут отрисовываться. Самый первый вариант выбирать не советую, так как это крайне неудобно. make nconfig вполне достаточно.
Это опции «досборки» ядра. Если вам позарез надо включить какую-то фичу или добавить модуль. Первые четыре опции отличаются только графикой, с помощью которой будут отрисовываться. Самый первый вариант выбирать не советую, так как это крайне неудобно. make nconfig вполне достаточно.
make localyesconfig это отдельная тема. Он похож на localmodconfig, но если первый все запущенные модули включит в ядро в виде модуля, то localyesconfig вкомпилирует эти модули в ядро. Это может быть очень болезненно, например, если у вас видеокарта NVIDIA и вы захотите использовать проприеритарные драйвера. По умолчанию nouveau (свободный драйвер нвидии) включён в ядро как модуль и его можно выгрузить с помощью команды modprobe -r nouveau. Собственно для работы проприеритарного драйвера он и должен быть выгружен. Если же драйвер вкомпилирован в ядро, то вытащить его оттуда уже нельзя и не видать вам игрулек с фпс выше 10.
Сама сборка займёт минут 20-40, в зависимости от мощности проца.
ВАЖНО!!!
После сборки я обнаружил то-ли баг, то-ли фичу. По умолчанию для ядра собираются так же и хедеры, в данном случае linux-pf-headers. И при сборке пакета они собираются, и находятся в той же папке где и собранный пакет с ядром. Но по какой-то странной причине они не ставятся вместе с ядром. Чтобы это недоразумание исправить, вам нужно зайти в папку где ядрышко собиралось и ручками доустановить оставшиеся пакеты:

cd ~/.cache/yay/linux-pf yay -U *.pkg.tar*
Если вы пакеты не поставите, то могут быть проблемы при запуске, установке драйверов, да и граб просто ядро не найдёт.
Самое интересное
Пора ставить драйвера!
Тем, у кого AMD или Intel бояться нечего, а вот пользующим нвидию лучше покрепче сжать сфинктер.
Если вы используете bumblebee или у вас только видеокарта нвидия, то вам достаточно поставить пакеты nvidia-pf и bbswitch-pf.
У меня такой мэджик почему-то не сработал, возможно из за того что я использую optimus-manager. На замену я поставил bbswitch-dkms и nvidia-dkms. Тут описано, что это за зверь. Самое важное уже во втором абзаце:
Это означает, что пользователь может не ждать, пока какая-то компания, проект или сопроводитель пакета выпустит новую версию модуля. После введения Pacman#Hooks пересборка модулей осуществляется автоматически во время обновления ядра.
То, что доктор прописал для нашего кастомного ядра.
ВАЖНО!!!
В манжаре нету nvidia-dkms, но есть тема на форуме, где ответил сам (!!!) oberon.
https://forum.manjaro.org/t/installation-linux-pf-in-manjaro/8642
В итоге всё решилось установкой двух арчовых пакетов. Раз вы досюда дочитали, то проще уж накатить арчик.